
I’ve never seen the computer you’re reading this story on, but I can tell you a lot about it. It runs on electricity. It uses binary logic to carry out programmed instructions. It shuttles information using materials known as semiconductors. Its brains are built on integrated circuit chips packed with tiny switches known as transistors.
In the nearly 70 years since the first modern digital computer was built, the above specs have become all but synonymous with computing. But they need not be. A computer is defined not by a particular set of hardware, but by being able to take information as input; to change, or “process,” the information in some controllable way; and to deliver new information as output. This information and the hardware that processes it can take an almost endless variety of physical forms. Over nearly two centuries, scientists and engineers have experimented with designs that use mechanical gears, chemical reactions, fluid flows, light, DNA, living cells, and synthetic cells.
Such now-unconventional means of computation collectively form the intuitively named realm of, well, unconventional computing. One expert has defined it as the study of “things which are already well forgotten or not discovered yet.” It is thus a field both anachronistic and ahead of its time.
But given the astounding success of conventional computing, which is now supported by a massive manufacturing industry, why study unconventional computing techniques at all? The answer, researchers say, is that one or more of these techniques could become conventional, in the not-so-distant future. Moore’s Law, which states that the number of transistors that can be squeezed onto a semiconductor chip of a given size doubles roughly every two years, has held true since the mid 1960s, but past progress is no guarantee of future success: Further attempts at miniaturization will soon run into the hard barrier of quantum physics, as transistors get so small they can no longer be made out of conventional materials. At that point, which could be no more than a decade away, new ideas will be needed.
So which unconventional technique will run our computers, phones, cars, and washing machines in the future? Here are a few possibilities.
Chemical Computing
A chemical reaction seems a natural paradigm for computation: It has inputs (reactants) and outputs (products), and some sort of processing happens during the reaction itself. While many reactions proceed in one direction only, limiting their potential as computers (which generally need to run programs again and again), Russian scientists Boris Belousov and Anatoly Zhabotinsky discovered in the 1950s and ’60s a class of chemical reactions, dubbed “BZ reactions,” that oscillate in time.
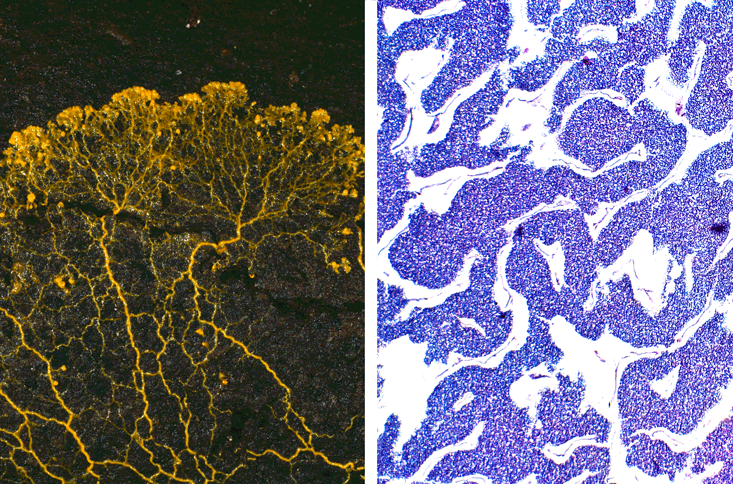
In the 1990s, Andrew Adamatzky at the University of the West of England, in Bristol, built on Belousov and Zhabotinsky’s work together with his colleagues, developing a way to excite BZ reactions with silver halide ions and control the propagation of chemical waves with light. By making separate wave fronts interact with each other, the researchers developed ways to carry out elementary computing logic. Information could be read out in the concentrations of the different chemicals at a given location.
Chemical computing is naturally parallel, Adamatzky says, with computations taking place simultaneously at every location along a reaction front. It is well adapted for certain kinds of problems that require exploring a large set of possibilities simultaneously, like computing the shortest path through a maze or street map. But, he admits, it is slow: Chemical reactions propagate on time scales of seconds or minutes, not the nanoseconds we’re used to from our electric circuits. As a result, no commercial technologies currently use chemical computing. But researchers have developed much faster semiconductor circuits inspired by chemical computing experiments.
Recently, Adamatzky has turned his attention to a biological medium: the slime mold Physarum polycephalum. Like BZ chemicals, slime molds are experts at spatially explicit problems. Adamatzky adds that they are easier to experiment with than finicky chemicals, and can solve a wider range of problems than chemicals have been able to tackle.
Wetware Computing
Nothing seems less compatible with a modern computer than the word “wet.” But wetware was nature’s computing medium for billions of years before a human first thought to etch a circuit into silicon. Cells can be thought of as a type of computer, in which DNA provides information storage, RNA represents input, ribosomes do processing, and proteins form the output. Wetware took a big step forward several hundred million years ago with the evolution of the neuron—a type of cell that takes chemical input, converts it to a traveling electrical signal and outputs further chemical signals. In a way, it’s remarkable that we have chosen to build an entirely new, inorganic computing architecture instead of using the organic one that nature built.
But as versatile as they are, cells are hard to program. In 1999, biomedical engineer William Ditto, then at the Georgia Institute of Technology and now at the University of Hawaii at Manoa took an early step together with his colleagues, programming a simple computer made from leech neurons to add two numbers together. They did this by controlling the electrical states of the neurons using inserted probes. But Ditto says living cells are much harder than electronic circuitry to manipulate, and scaling wetware up to fully functional computing circuits is a major challenge.
Recently Ditto has moved away from working with actual cells, which inconveniently need to be kept alive, to circuitry that mimics cells. One of the advantages that cells and gene networks provide is that they are nonlinear, or “chaotic,” systems, which means they respond very differently to slightly varying inputs. Chaotic circuitry’s sensitivity to initial conditions could make its output unreliable, but Ditto says he has found a way to turn that into a strength. “It turns out we can design ‘with’ this sensitivity to get the system to stay on the pattern we like very easily,” Ditto says.
Ditto has spun a company off his research, called Chaologix. It has developed a neuron-inspired, chaos-based silicon chip for applications that require a high level of security. Conventional chips embedded into credit cards and other applications generate electromagnetic fields and consume power in ways that can reveal encoded information to a hacker. Ditto says the way the Chaologix chip consumes power makes it harder to hack.
Fluidic Computing
The field of microfluidics uses tiny volumes of fluids transported through ultrathin channels. Manu Prakash of Stanford University has used microfluidics to develop what he calls “bubble logic.” Information can be encoded in whether a bubble appears in one channel or another, or simply in whether a bubble is present or absent in a channel. Using such ideas, Prakash has built bubble-processing logic gates and simple circuits.
Microfluidics will probably not replace silicon as a general-purpose computing platform, says Duke University’s Krishnendu Chakrabarty: Liquid moves far too slowly. But if the input is already in the form of liquid—say a drop of blood, or lake water—microfluidics offers a way to process it without the costly step of translating data into an electrical signal first. For instance, a blood droplet could be split, sent through multiple channels, and reacted with multiple chemicals in parallel to scan for a particular disease marker or drug. Fluidics’ relatively slow speed is not a hindrance in such biochemical applications because chemical reactions proceed at similar speeds.

Future applications could involve a hybrid of conventional electronic computer control, microfluidic data processing and optical readout of results. Duke University researchers have built chips in which electronic circuitry controls liquid droplets’ motion using tiny electrical forces that change whether droplets are attracted to or repelled by microfluidic channel surfaces.1 A spinoff from Duke’s Microfluidic Research Lab called Advanced Liquid Logics was acquired in 2013 by the life science technology firm Illumina. “It’s a narrow, well-defined application domain,” Chakrabarty says, but, he adds, one “that is now maturing.”
Ternary Computing
The techniques discussed so far relate to the physical devices that represent and manipulate information in computers. But information architecture itself can also be unconventional. The familiar 0s and 1s of binary logic have natural advantages—for one, information encoded this way can be transmitted reliably even over channels with a lot of noise. (Think how much easier it is to tell someone if a light is on or off versus telling that person the level at which you’ve set a dimmer switch.) And hardware implementation of binary can also be easier, especially for the magnetic memory that is only now fading from the scene: Magnets are bipolar and lend themselves to being flipped 180 degrees.
Ternary logic—using bits (or “trits”) with three possible values—is one alternative to binary. The digits could be 0, 1, and 2, but “balanced ternary” arithmetic with -1, 0, and 1 offers certain advantages. Some have argued that ternary could be more efficient than binary or than any other integer base at storing and processing information (using a measure called “radix economy”).
Even under the best of circumstances, however, this advantage is small and the hurdles ternary would need to overcome to compete with binary are large, says University of Iowa computer scientist Douglas Jones. Partly this is because no one has developed efficient ways to carry out some basic computing functions in ternary. For instance, computers add large numbers using what is called “carry lookahead logic,” which adds each column in a sum simultaneously and is much faster than the “ripple carry” method we learn in grade school. A ternary lookahead algorithm does not yet exist, and other algorithms that would be needed for ternary to be practical are also missing.
Binary logic is also baked into hundreds of billions of dollars of computing infrastructure, and adapting this infrastructure for ternary computing would require starting essentially from scratch. “The compatibility problem is why, if I had a billion dollars in hand right now, I probably wouldn’t invest in this expecting any return on investment,” says Jones.
However, ternary computing may be spurred on by a new device called the memristor. In the early 1970s, University of California, Berkeley physicist Leon Chua envisioned an electronic circuit component whose electrical resistance would depend on the electric current that had recently flowed through it. In other words, the device’s resistance could act as a memory. In 2008, scientists at HP Labs in Palo Alto, California reported detecting this memristive effect in thin-film titanium dioxide wafers. Since then, scientists around the world have been working to develop a memristor that could be mass-produced for computing applications. Because memristors can take on many different resistance values and are non-volatile (in other words, they continue to store information even after the power to them is turned off), they can encode information in binary, ternary, or even higher-number bases. Memristors might become one of the industry’s hopes for extending Moore’s Law beyond the age of the silicon transistor.
Gabriel Popkin is a science and environmental writer based in Mount Rainier, Maryland. He has written for The New York Times, Science, Slate, and Physics World, among others.